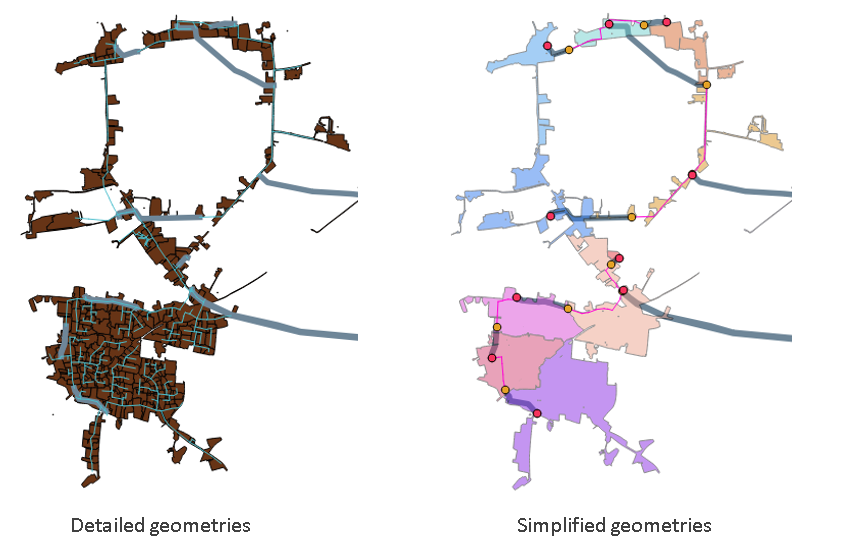
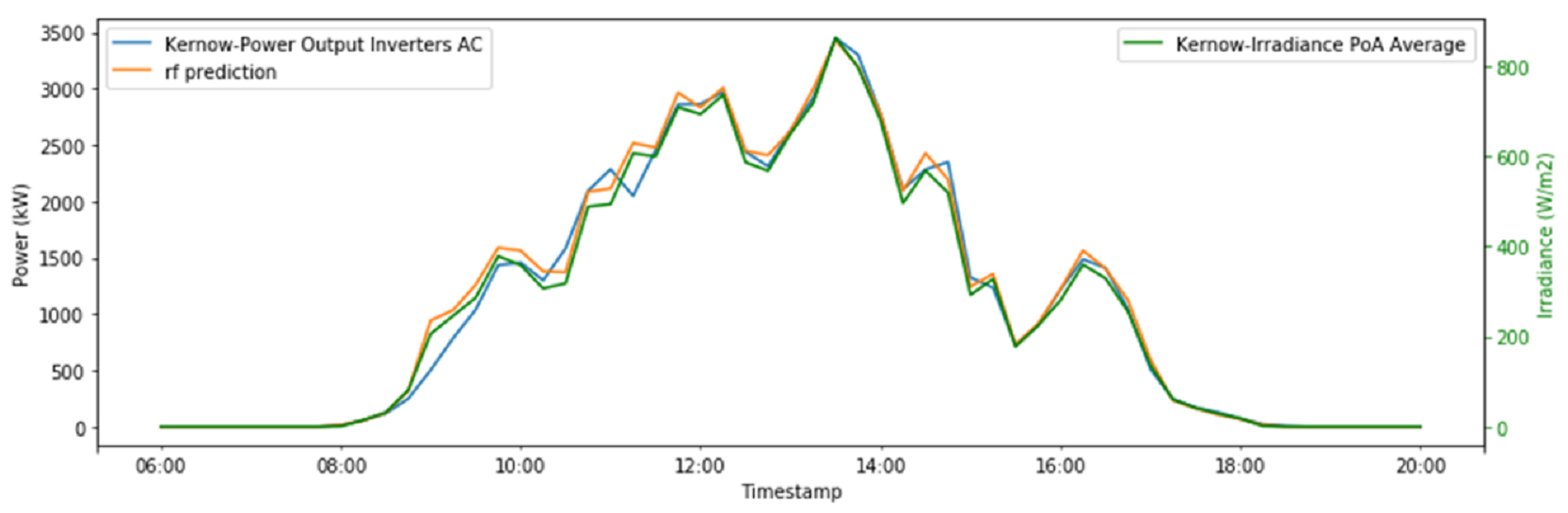
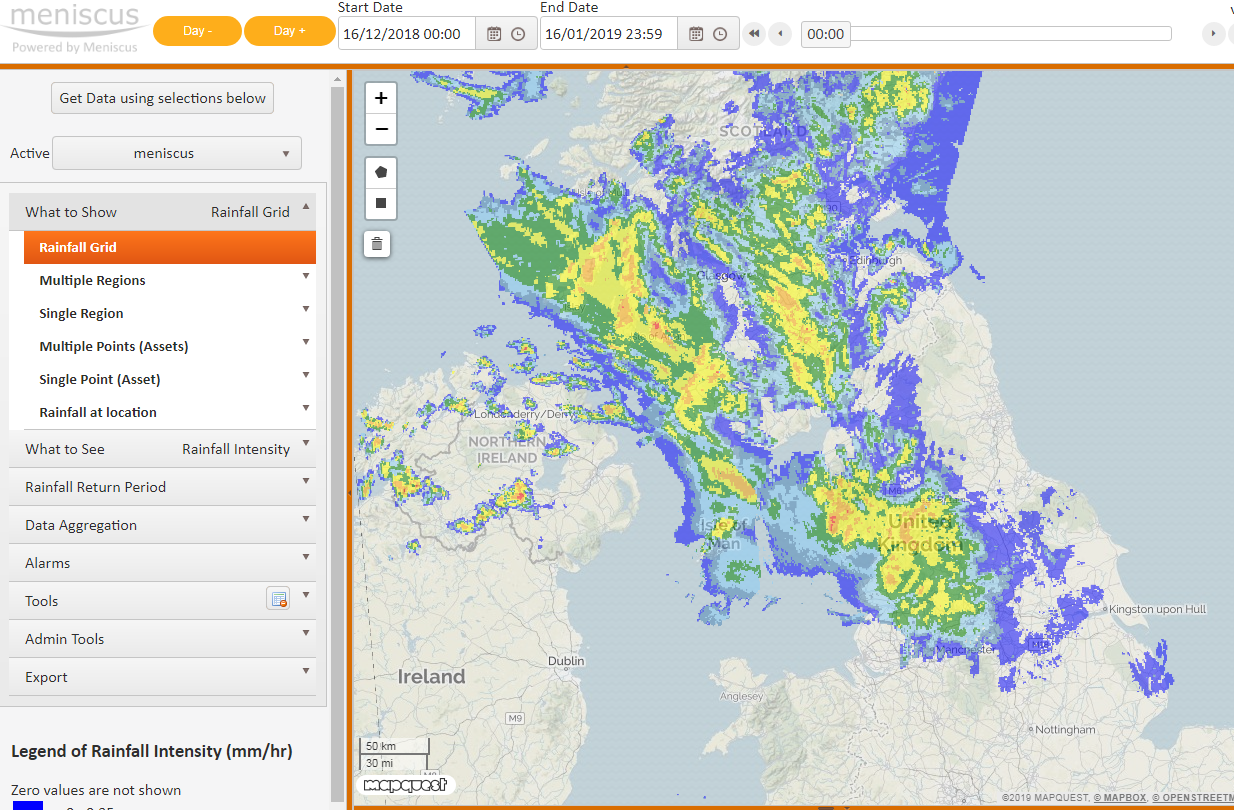
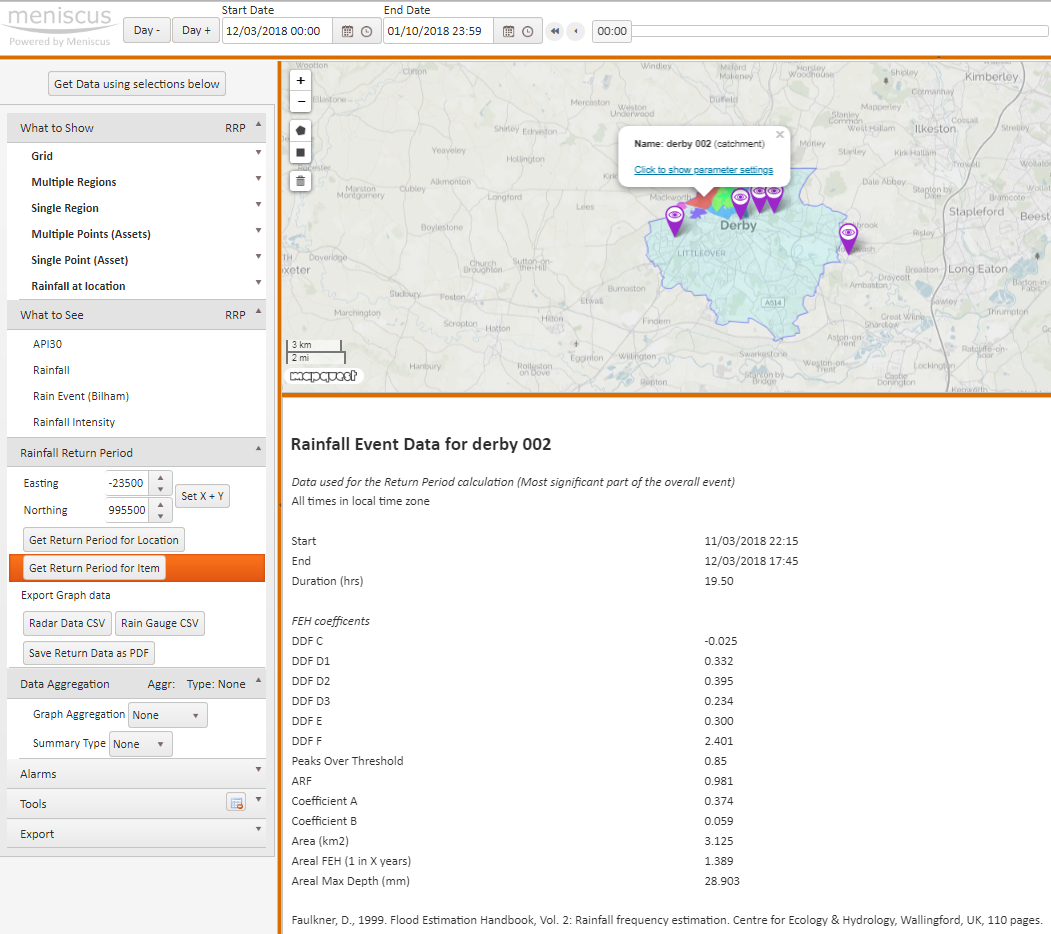
Support for rich and extensible data types
Introduction
This is part of a series of articles where we describe the way the Meniscus Analytics Platform (MAP) works. Theses articles jump into the features that make MAP different to other analytics applications by providing an Integrated Analytics Stack delivering real time analytics. IN this article we talk about extensible data types.
This article discusses how and why having extensible data types is a real benefit when developing your analytics applications
Why are extensible data types important?
Being able to use a wide variety of ‘standard’ data types, but also to create your own, delivers lots of benefits.
- Provides flexibility. During the import stage you can re-process and store the initial raw data into a ‘pre-processed’ data type. When you want to use this data to deliver a calculation or other use then the data is already configured and available in exactly the format you want
- Greatly increases data processing and calculation times.
- Extensible data types give you the ability to control how you store and process your raw data
Examples of data types supported by MAP
We have a number of ‘standard’ extensible data types already configured in MAP but there is no limit to the number or variety that you can create.
- Data Grid. One of the most important for our MAP Rain solution. Processes data in any size of two dimensional grid. Used for radar and forecast rainfall data, satellite imagery and the like
- Block Grid. Used in conjunction with a Data Grid. Breaks a two dimensional Data Grid into a smaller three dimensional Block. Used for speeding up the processing of Data Grids by ensuring MAP only processes relevant data. See article on lazy loading of data sets
- Vector Grid. Similar to a Data Grid but provides a two dimensional grid but includes vector and direction data as well. Used for processing grids of forecast wind speed and direction data.
- Rainfall Location. Holds the location of a point of interest (Latitude and Longitude) as well as the current and historic rainfall data for that Location. Used in MAP Rain
- Float – standard time series. This is a standard data type for processing time series data. Contains a Date/Time Value pair
- Journey. Used to create and store a sequence of locations along the route of a journey. We use this data type to predict rainfall along this route using our Hyperlocal rainfall product
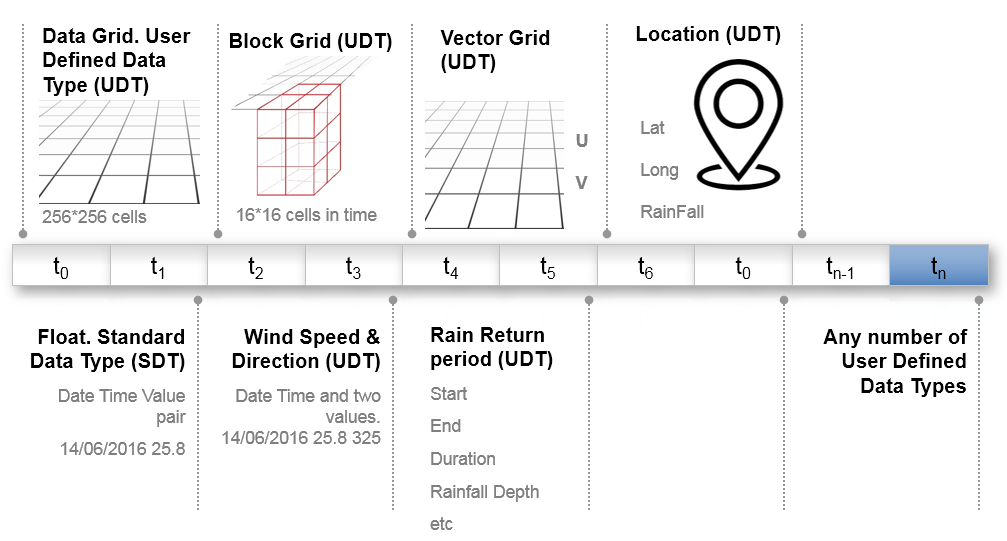
Examples of data types
About MAP
MAP is an Integrated Analytics Stack providing a framework for users to create and deploy calculations at scale using any source of raw data. MAP is based on IOT principles and uses Items as the underlying building blocks to store either RAW or CALCulated data. So, users create an Entity Template or Thing using these Items and then replicate this template hundreds of thousands of times using an ItemFactory.