Introduction
This is part of a series of articles where we describe the way the Meniscus Analytics Platform (MAP) works. Theses articles jump into the features that make MAP different to other analytics applications by providing an Integrated Analytics Stack delivering real time analytics. In this article we discuss Data Blocks and Data Versioning.
In delivering real time analytics, disk IOPS (Input/output Operations Per Second) is one of the main rate limiting steps in achieving the calculation speeds required when processing high volume and high velocity raw data. An example of such a data is radar rainfall data where new values covering a large area arrive every 5 minutes.
To help reduce disk IOPS, we developed the concepts of Data Blocks and Data Versioning into MAP to drastically speed up data access, increase calculation speed and reduce the volume of data written back to the database.
Data Blocks
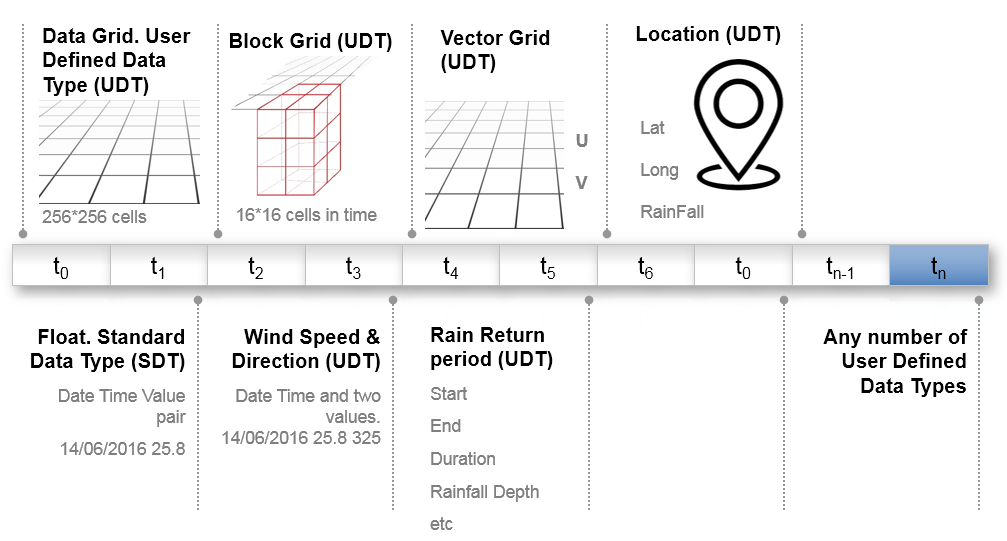
Rather than loading and persisting all data for an Item, data can be broken up into chunks called Blocks. So, only the chunks of data that are demanded for a query, or as an input to a calculation, are loaded from the database (i.e. delay loading), and only the chunks of data that actually change need to be persisted. Blocks are typically used with unbounded, time-related data such as sample arrays, where the size of a Block is limited and the maximum number of Block samples depends on the size of a sample. This provides efficiencies in real-time processing, whereby data changes are localised and typically at the end of the data.
Data Blocks are transparent to the user. It is purely an internal mechanism to reduce traffic to/from the database. When requested or persisted, Data Blocks are held in memory for a time. This ensures future retrieval is temporarily faster as the data is expected to be in demand.
Data Versioning
Data Blocks are complimented by the MAP concept of Data Versioning. All Item data in MAP is versioned, including Blocks (as such referred to as child data). A version is simply a unique timestamp. It allows users to query for the relative age of data. Specifically, when it last changed, and for calculated Items when the last calculation started and completed. A client application can then tell if data has changed without having to load the data itself. There are additional non-data versions on an Item. I.E when its properties or list of child items last changed.
It is this versioning technique that allows MAP to efficiently detect when calculated items need recalculating (referred to as dirtying as calculation).
About MAP
MAP is an Integrated Analytics Stack providing a framework for users to create and deploy calculations at scale using any source of raw data. MAP is based on IOT principles and uses Items as the underlying building blocks to store either RAW or CALCulated data. So, users create an Entity Template or Thing using these Items and then replicate this template hundreds of thousands of times using an ItemFactory.
For more information on MAP then click here